2025.01.20 DeepSeek-R1 发布

根据官方信息DeepSeek R1 可以看到提供多个版本,包括完整版(671B 参数)和蒸馏版(1.5B 到 70B 参数)
完整版性能强大,但需要极高的硬件配置
蒸馏版则更适合普通用户,硬件要求较低
| 特性 | 蒸馏版 | 完整版 |
|---|---|---|
| 参数量 | 参数量较少(如 1.5B、7B),性能接近完整版但略有下降。 | 参数量较大(如 32B、70B),性能最强。 |
| 硬件需求 | 显存和内存需求较低,适合低配硬件。 | 显存和内存需求较高,需高端硬件支持。 |
| 适用场景 | 适合轻量级任务和资源有限的设备。 | 适合高精度任务和专业场景。 |
看看蒸馏模型
| 模型版本 | 参数量 | 特点 |
|---|---|---|
deepseek-r1:1.5b | 1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
deepseek-r1:7b | 7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
deepseek-r1:8b | 8B | 略高于 7B 模型,性能稍强,适合需要更高精度的场景。 |
deepseek-r1:14b | 14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
deepseek-r1:32b | 32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
deepseek-r1:70b | 70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
进一步的模型细分还分为量化版
| 模型版本 | 参数量 | 特点 |
|---|---|---|
deepseek-r1:1.5b-qwen-distill-q4_K_M | 1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
deepseek-r1:7b-qwen-distill-q4_K_M | 7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
deepseek-r1:8b-llama-distill-q4_K_M | 8B | 略高于 7B 模型,性能稍强,适合需要更高精度的场景。 |
deepseek-r1:14b-qwen-distill-q4_K_M | 14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
deepseek-r1:32b-qwen-distill-q4_K_M | 32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
deepseek-r1:70b-llama-distill-q4_K_M | 70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
硬件配置要求
- Windows 配置:
- 最低要求:NVIDIA GTX 1650 4GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
- 推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
- 高性能配置:NVIDIA RTX 3090 24GB 或 AMD RX 7900 XTX 24GB,64GB 内存,200GB NVMe SSD
- Linux 配置:
- 最低要求:NVIDIA GTX 1660 6GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
- 推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
- 高性能配置:NVIDIA A100 40GB 或 AMD MI250X 128GB,128GB 内存,200GB NVMe SSD
- Mac 配置:
- 最低要求:M2 MacBook Air(8GB 内存)
- 推荐配置:M2/M3 MacBook Pro(16GB 内存)
- 高性能配置:M2 Max/Ultra Mac Studio(64GB 内存)
本地部署的好处:
- 隐私:您的数据保存在本地的设备上,不会通过外部服务器
- 离线使用:下载模型后无需互联网连接
- 经济高效:无 API 成本或使用限制
- 低延迟:直接访问,无网络延迟
- 自定义:完全控制模型参数和设置
部署可以使用Ollama、LM Studio、Docker等进行部署
- Ollama:
- 支持 Windows、Linux 和 Mac 系统,提供命令行和 Docker 部署方式
- 使用命令下载并运行模型
- LM Studio:
- 支持 Windows 和 Mac,提供可视化界面,适合新手用户
- 支持 CPU+GPU 混合推理,优化低配硬件性能
- Docker:
- 支持 Linux 和 Windows,适合高级用户。
- 使用命令启动容器
本地部署:Ollama 安装
先下一个Ollama
https://ollama.com/download/windows
国内网络很慢怎么办?推荐使用玛卡巴卡加速器
https://www.makabaka.one
注册送48小时1TB下载流量
下载好以后双击下载的安装包,按照提示完成安装。默认安装路径为C:\Users\{你的电脑账户名}\AppData\Local\Programs\Ollama
请确保你的C盘有足够空间
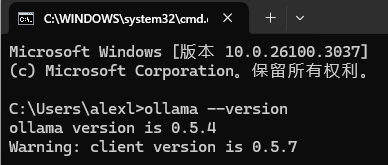
如何验证ollama已经安装好了呢?
打开命令提示符或 PowerShell,输入以下命令验证安装是否成功:
ollama –version
如果显示版本号,则说明安装成功
更改安装路径(可选)
如果需要将 Ollama 安装到非默认路径,可以在安装时通过命令行指定路径,例如:
OllamaSetup.exe /DIR=”d:\some\location”
这样可以将 Ollama 安装到指定的目录
安装包界面
进入ollama后我们会看到命令行
之后就可以输入命令进行安装了,用哪些代码呢?
先看一下你设备的显卡和内存要求,参数量越小的越垃圾,适配的显卡越低级
| 模型名称 | 参数量 | 大小 | VRAM (Approx.) | 推荐 Mac 配置 | 推荐 Windows/Linux 配置 |
|---|---|---|---|---|---|
deepseek-r1:1.5b | 1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
deepseek-r1:7b | 7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
deepseek-r1:8b | 8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
deepseek-r1:14b | 14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
deepseek-r1:32b | 32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
deepseek-r1:70b | 70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
下面这是安装命令,你只需要找到一个模型安装即可
1.5B Qwen DeepSeek R1 安装命令
ollama run deepseek-r1:1.5b
7B Qwen DeepSeek R1 安装命令
ollama run deepseek-r1:7b
8B Llama DeepSeek R1 安装命令
ollama run deepseek-r1:8b
14B Qwen DeepSeek R1 安装命令
ollama run deepseek-r1:14b
32B Qwen DeepSeek R1 安装命令
ollama run deepseek-r1:32b
70B Llama DeepSeek R1 安装命令
ollama run deepseek-r1:70b
如果你想安装其他模型,可以去ollama官网查看,选择需要的模型复制命令进行安装
https://ollama.com/search
如果下载慢,记得用玛卡巴卡加速器,开TUN模式,即虚拟网卡模式,全局接管下载流量,就很快了
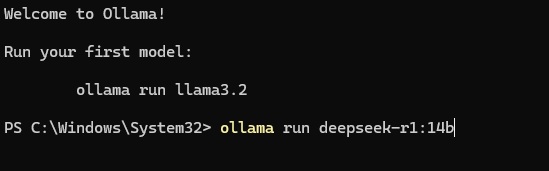
这里我电脑的内存是32G,显卡显存10GB,下一个14B玩玩
ollama run deepseek-r1:14b
然后就可以直接提问了
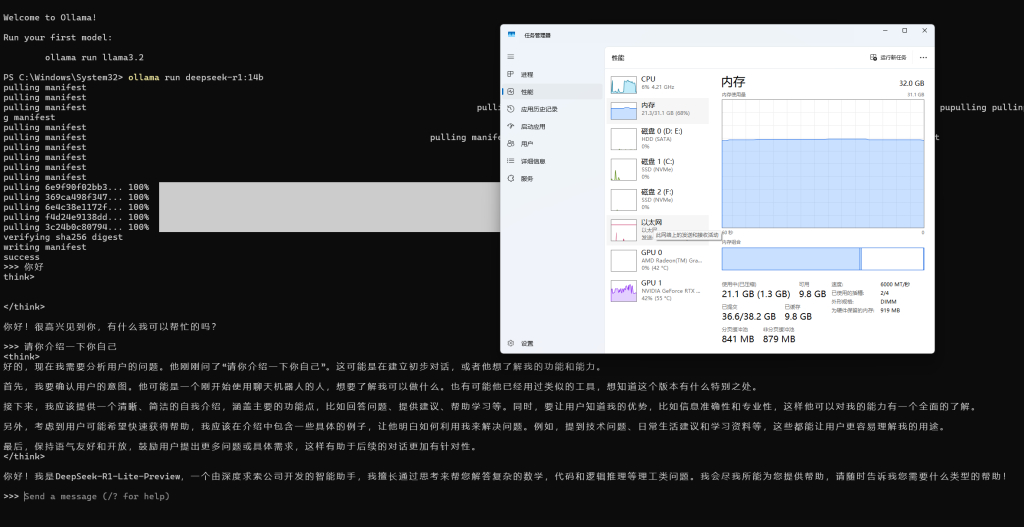
根据测试来看,14B的deepseek蒸馏模型需要的内存量在20-40GB区间,显卡显存不能低于8GB,可以说非常震撼。
PS:到这里你应该知道ollama是干啥的吧,这是一个管理和运行大模型的软件
当然,这种命令行的操作肯定不适合用户,普通人谁会玩命令行啊,我们需要对接一个前端的可视化界面UI
安装AnythingLLM
AnythingLLM官网:https://anythingllm.com/
结合自己的电脑系统下载相关版本
选择安装位置
耐心等待安装完成
这里右边箭头跳过
读协议环节,跳过
输入邮箱、选择For my personal use,然后继续
输入项目名字,随便自己定
然后就可以了
将Deepseek R1模型对接Anything LLM
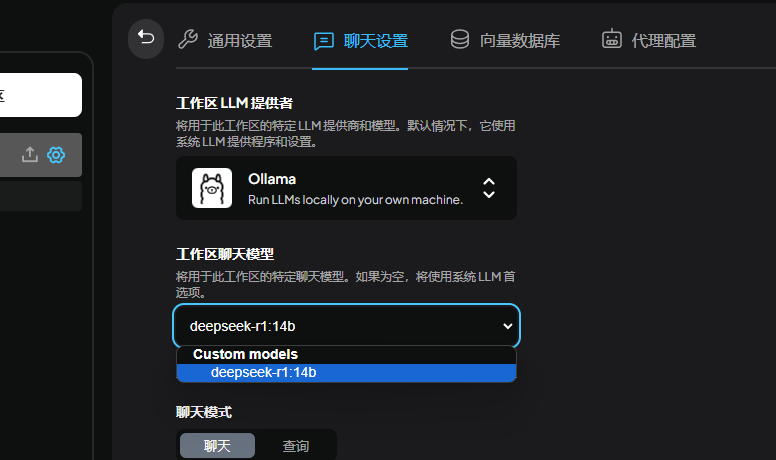
找到AnythingLLM客户端刚才新创建的项目,选择设置-聊天设置
选择LLM模型
找到Ollama
这里请确保ollama运行中,如果报错,就说明ollama没运行,你需要先关掉AnythingLLM,先启动ollama,再打开AnythingLLM
这里科普一下:
ollama默认运行在本地11434 端口上,即 http://127.0.0.1:11434
如果你启动AnythingLLM的时候无法打开ollama,那么大概率本地11434端口被占用了,如何排查呢?
我们在AnythingLLM运行的时候,进入CMD,输入ollama serve,会提示127.0.0.1:11434端口被占用

以我的这台电脑举例子,我输入 tasklist | findstr 23748 来查找占用 11434 端口的进程,上面显示进程PID是23748,接下来就可以进入任务管理器根据这个PID = 23748的进程了
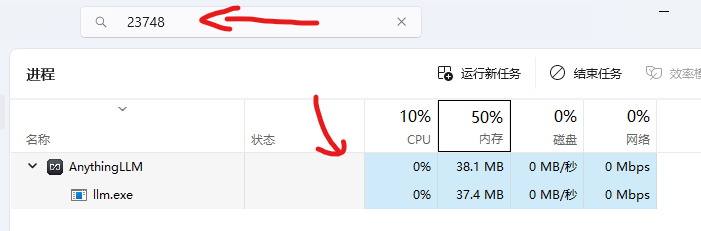
可以看到还是这个AnythingLLM在占用,我们彻底退出AnythingLLM,然后再启动ollama就可以了
这是先启动ollama后打开AnythingLLM的配置页面
可以看到这里就可以选择我们之前安装的deepseek R1模型了
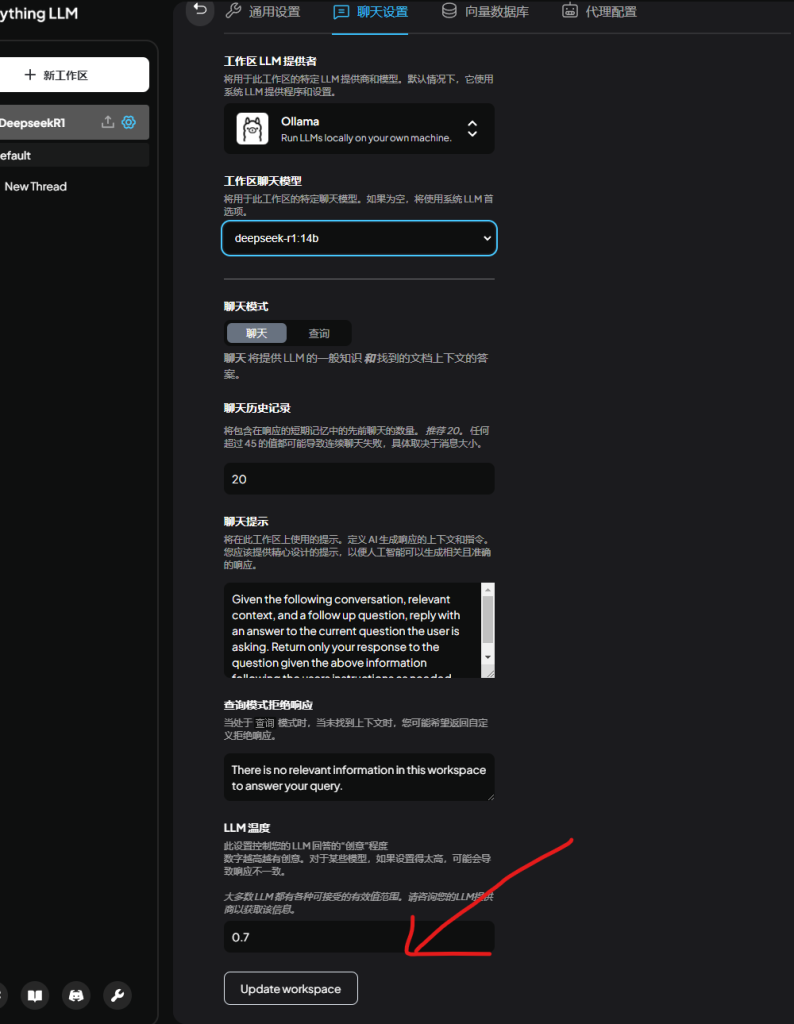
注意,修改之后一定要点击最下面的 Update workspace,才能完成更改!
这是deepseek 14b运行时的基本状态,可以看到显存需要至少40GB,我的显卡是8G的,其余的都要交给内存来处理,这是一个家用的1W块的电脑配置,只能带中低训练量的deepseek
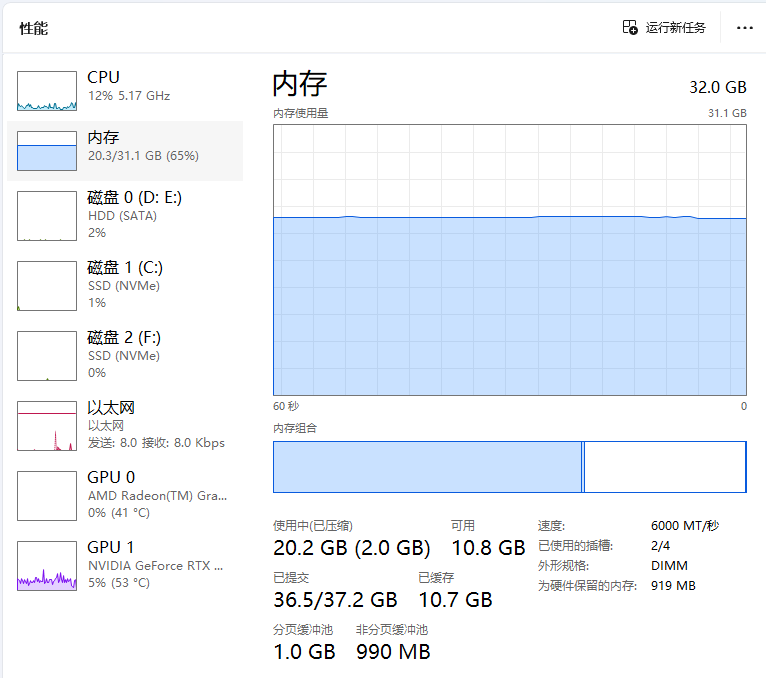
同时推理速度较慢,让它做研究生题目的时候还是有点问题,顶多适合文字处理类的工作!做AI助手还是挺棒的!
本地部署的deepseek支持的功能
AI对话、图文识别、上传多文档分析这些都可以实现
逻辑推理:简单的文字游戏、入门逻辑题目基本没有问题,但是复杂的研究生博士生数学题还是有难度
本地自建知识库:支持上传本地文件构建数据库、向量数据库、文本分割、语音转化
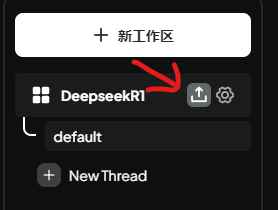
这里推荐一下玛卡巴卡加速器,10G下载带宽,注册就送48小时1TB流量
值得使用->https://www.makabaka.one